今天这篇文章我想谈下堆表上特有的性能问题:转发记录(Forwarding Records)。首先我们要澄清下什么是堆表:堆表就是没有聚集索引定义的表。它对插入新记录非常快,但当你读取数据时非常慢。读取数据会在你的存储子系统上引入,有时候当你碰到转发记录,它会进一步降低你的读取性能。
为什么会有转发记录?
当堆表里的记录需要移动到不同的物理位置时,SQL Server使用转发记录。假设你有一个变长列的表,首先你在堆表里插入一些记录,这个时候你没有在变长列里存储任何数据:
1 -- Create a table to demonstrate forwarding records 2 CREATE TABLE HeapTable 3 ( 4 Col1 INT IDENTITY(1, 1), 5 Col2 CHAR(2000), 6 Col3 VARCHAR(1000) 7 ) 8 GO 9 10 -- Insert 4 records - those will fit into one page11 INSERT INTO HeapTable VALUES12 (13 REPLICATE('1', 2000),14 ''15 ),16 (17 REPLICATE('2', 2000),18 ''19 ),20 (21 REPLICATE('3', 2000),22 ''23 ),24 (25 REPLICATE('4', 2000),26 ''27 )28 GO 当你在变长列执行UPDATE语句时,想象下会发生什么?在那个情况下SQL Server可能需要扩展这个记录,因为记录大小更长了,其他记录必须从同个数据页移走。
1 -- Let's update the table and expand each row of the table2 UPDATE HeapTable3 SET Col3 = REPLICATE('5', 1000)4 GO 在那个情况下,SQL Server在原始位置留下称为转发记录,它指向记录最终存储的新位置。
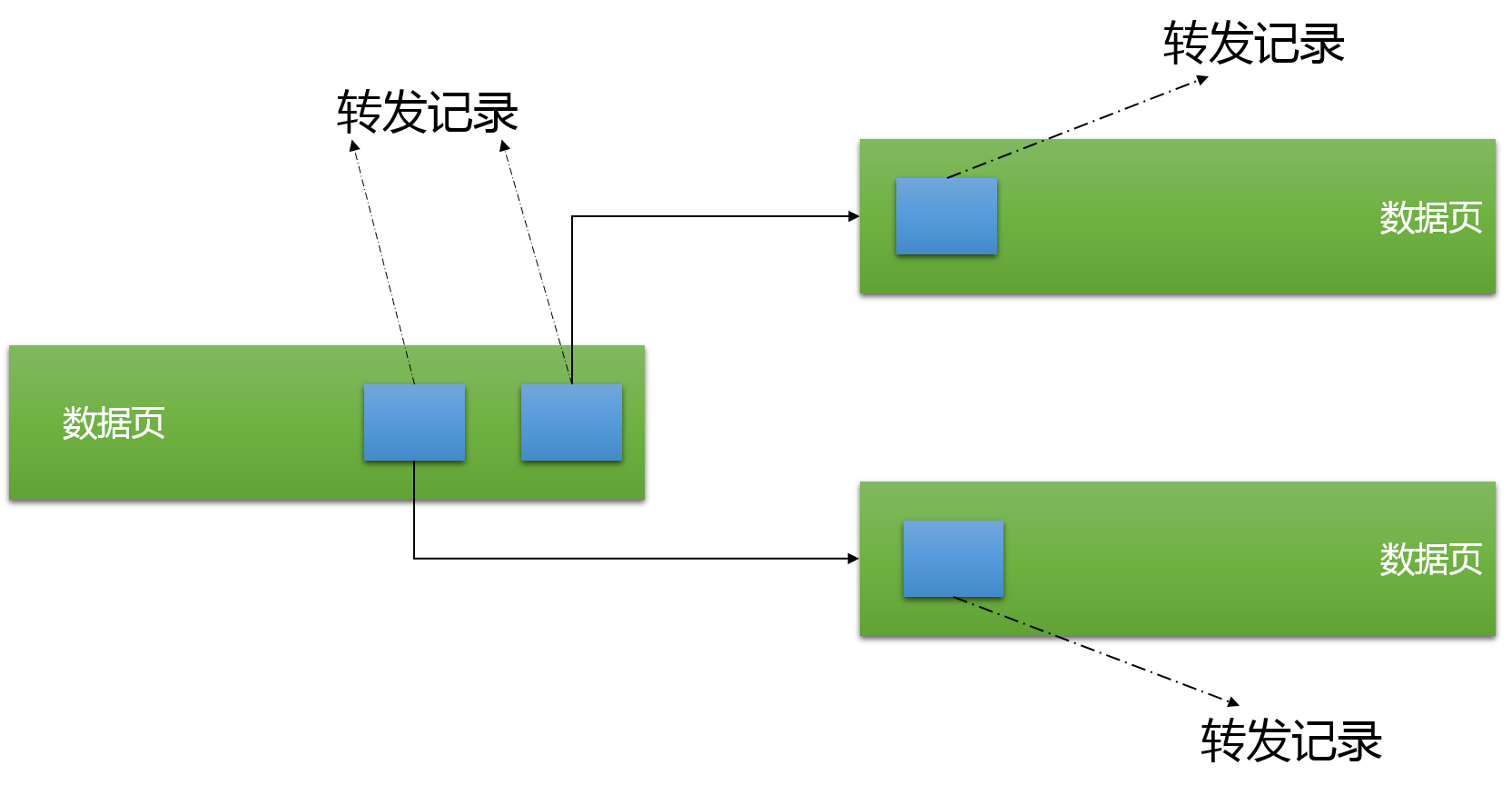
SQL Server需要使用这个方法来避免更新同个表上所有非聚集索引。你可能知道,当你在堆表上创建非聚集索引时,在叶子层,非聚集索引指向记录数据存储的物理位置。没有抓发记录的话,所有这些指针都要改变,这会大幅度降低你的性能。
如何修正转发记录?
为了找出表里是否包含转发记录,你可以使用DMF sys.dm_db_index_physical_stats。当你在堆表上调用这个函数并传入DETAILED模式,SQL Server通过forwarded_record_count列告诉你表上的转发记录数。
1 -- Check the forwarding record count through sys.dm_db_index_physical_stats 2 SELECT 3 index_type_desc, 4 page_count, 5 avg_page_space_used_in_percent, 6 avg_record_size_in_bytes, 7 forwarded_record_count 8 FROM sys.dm_db_index_physical_stats 9 (10 DB_ID('ALLOCATIONDB'), 11 OBJECT_ID('HeapTable'),12 NULL, 13 NULL, 14 'DETAILED'15 )16 GO 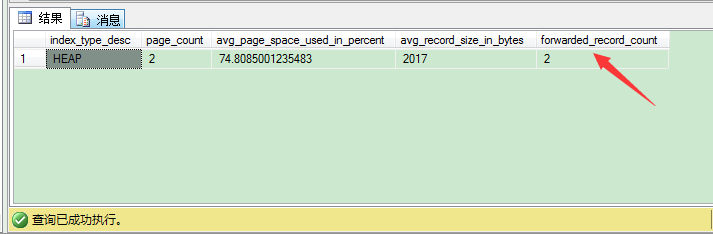
可以看到,表上有2条转发记录,在4条记录之外。为了去掉这些转发记录,你可以重建表。
1 -- Rebuild the heap table to get rid of the Forwarding Records2 ALTER TABLE HeapTable REBUILD3 GO
再次运行刚才的查询,你会发现转发记录已经消失。
1 -- Check the forwarding record count through sys.dm_db_index_physical_stats 2 SELECT 3 index_type_desc, 4 page_count, 5 avg_page_space_used_in_percent, 6 avg_record_size_in_bytes, 7 forwarded_record_count 8 FROM sys.dm_db_index_physical_stats 9 (10 DB_ID('ALLOCATIONDB'), 11 OBJECT_ID('HeapTable'),12 NULL, 13 NULL, 14 'DETAILED'15 )16 GO 
DBA总会考虑到索引碎片,索引重建和索引重新组织操作。但没有人想过堆表里的转发记录。如果你维护数据库,经常检查下堆表上的转发记录数,保证始终有最好的性能,这是个非常好的想法。
小结
在这个文章里你看到了堆表上转发记录是咋样,它是如何降低的记录读取,因为需要额外的逻辑读。当我为数据库进行健康检查时,我在检查堆表时,总会看下转发记录数。
相信我:数据库里会有巨大数量的堆表,在生产系统里也会有很多转发记录,但DBA们并没意识到这个副作用。作为第一经验,我经常推荐在表上建立聚集索引来避免转发记录。当然在一些特定场景里,例如,在这里你可以使用堆表来避免这个问题,但大多数情况下,在表上建立聚集索引还是非常有用的。